With the spread of COVID-19 becoming an evermore assertive force in our lives, the healthcare data science community has an opportunity to play an important role in the mitigation of this emerging pandemic. History has shown response to such diseases can drastically alter the worst effects of such diseases.
Written by Joseph Gartner, Director of Data Science, ClosedLoop
Originally published March 17, 2020. Last updated June 19, 2023. • 5 min read
With the spread of COVID-19 becoming an evermore assertive force in our lives, the healthcare data science community has an opportunity to play an important role in the mitigation of this emerging pandemic. History has shown response to such diseases can drastically alter the worst effects of such diseases. Many cities have imposed social distancing measures, closing any place where large numbers of people gather, and further measures can be taken to help isolate and protect the most vulnerable amongst the population. In order to do so, we must first identify who is at greatest risk, which motivated my team to create an open sourced project, the COVID-19 Vulnerability Index.
The C-19 Index is an open source, AI-based predictive model that identifies people who are likely to have a heightened vulnerability to severe complications from COVID-19. The C-19 Index is intended to help hospitals, federal / state / local public health agencies and other healthcare organizations in their work to identify, plan for, respond to, and reduce the impact of COVID-19 in their communities. In this post, we’ll be going over the high level details of this open sourced project. For a more detailed description of the data selection and model building, please see our white paper.
Step 1 – Making a Labeled Data Set
Data on COVID-19 hospitalizations does not yet exist. While data begins to emerge, we can look at the affected populations and events that serve as proxies for the real event. Given that the disease’s worst outcomes are concentrated on the elderly, we can focus on medicare billing data. Instead of predicting COVID-19 hospitalizations, we can instead predict proxy medical events, specifically hospitalizations due to respiratory infections. Examples include, Pneumonia, Influenza, and Acute bronchitis. We identify these labels by parsing medical billing data and searching for specific ICD-10 codes that describe these types of events. All predictions are made on a specific day. From a particular day, we look back in time 15 months for features. We exclude any events happening within three months of the prediction date, due to the lag in medical claims data reporting. Any diagnoses within the last year become the features we use in all of our models.
Step 2 – Models
There are hosts of model considerations that need to be made with these kinds of projects. Ultimately, we wanted these models to balance being effective as possible, and still accessible to healthcare data scientists as quickly as possible. One of the reasons for choosing the data that we used is because medicare claims data is widely available to healthcare data scientists. If your organization has access to additional data sources, you may observe performance increases by incorporating such information. Balancing those considerations led us to create 3 models based on the ease of adoption and model effectiveness.
The first, is a logistic regression model using a small number of features. At ClosedLoop, we use the standard python data science stack. The motivation for a very simple model is that it can be ported to environments like R or SAS without having to read or write a line of python. At low alert rates, the model performs close to parity with the more sophisticated versions of the model. The aforementioned white paper has all of the weights for the limited feature set, so it can be ported over by hand.
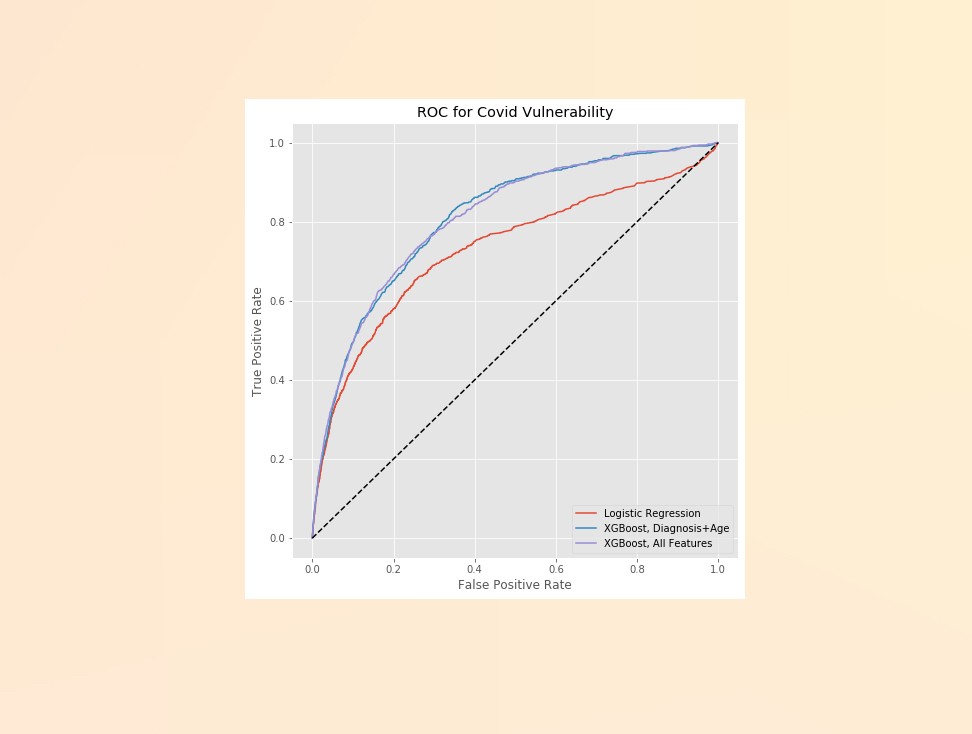
The next two models are both made using XGBoost. XGBoost consistently gives the best performance for making predictions on well structured data, and given the right data transformation, medical billing data has that structure. The first XGBoost model is featured in our open sourced package. A pickled version of the model exists, so you simply need to build a data transformation pipeline that will get your billing data into the format specified in the repo. If you can build a function that will parse your data for a specific code, then you can simply iterate through all of the codes. That’s the reason we selected a limited feature set for the open sourced model. It’s very effective, while still requiring only a reasonable level of lift from the data pipeline standpoint. We’re also giving healthcare organizations access to our model within the platform. This version of the model uses full diagnosis history, plus a large set of engineered features. Note, the ROC curve shows that the open source version has nearly identical performance as the version contained in our platform.
ROC curve comparing performance of all three models.
Conclusion
The whole world is participating in a fight against this pandemic. The healthcare data science community can have a big impact on combating this disease. There have been many excellent efforts to use data visualization and monte carlo simulations to help combat the spread of this pandemic. We feel our model addresses a complimentary and important aspect of health policy, identifying those most at risk. By combining the efforts of these and many other excellent efforts in the healthcare technology space, we hope to mitigate the effects of this terrible disease.
If reading this article has given you ideas for ways in which you’d like to contribute, we encourage you to fork our repository. If you are in the healthcare data science community, please do use the tool, and if you want to get in touch, feel free to head over to our C-19 Index for more information.
Interested in reading more about the impact of COVID-19 and the opportunity for AI to help alleviate some of the burden? Check out these related posts:
Artificial intelligence (AI) and machine learning (ML) are increasingly used in healthcare to combat unsustainable spending and produce better outcome...
COVID-19 simultaneously exacerbated existing health disparities and introduced entirely new ones. The pandemic disproportionately impacted people of c...
11 min read
Make AI/ML a core element of your care strategy.
Get in touch today to see the ClosedLoop platform in action.